When you build or update a website, it's a good idea to check that all the links on your webpages are OK. An excellent tool for doing this under Linux is the aptly named linkchecker, a GPL-licensed, command-line program.
However, 'OK' has more than one meaning. While linkchecker can check the URL you specify to see if it's properly formed and not broken, it can't tell you if the link points to the wrong URL.
For example, the page might say that if you click the link text 'page A' you'll be taken to page A, but the click actually takes you to page B:
Right
Click to go to page A
Wrong
Click to go to page A
Is there a way to check for misdirections like this one, besides checking each link by clicking? The answer is 'yes, maybe, sometimes', as explained below.
#A horrible example
Last year I built a website with more than 9000 internal links, i.e. links that take the user to another place on the same website. Thousands of those links went to particular entries on a bibliography webpage, bibliography.html, and each entry had an associated anchor. For example, a 2010 article by Bloggs in the bibliography would have the anchor . A page at the same level as bibiography.html could contain the link Bloggs 2010.
But were there any misdirected links, such as Bloggs 2010? To find out, I used a combination of a command line tool, a text editor and a spreadsheet to check those thousands of links and save hours of clicking!
#Grabbing the URLs and link texts
The first step was to harvest all the bibliography page links and their clickable texts from an offline version of the website. For example, to grab all such links in the website's 'species' folder, I navigated to the website in a terminal and entered the following command:
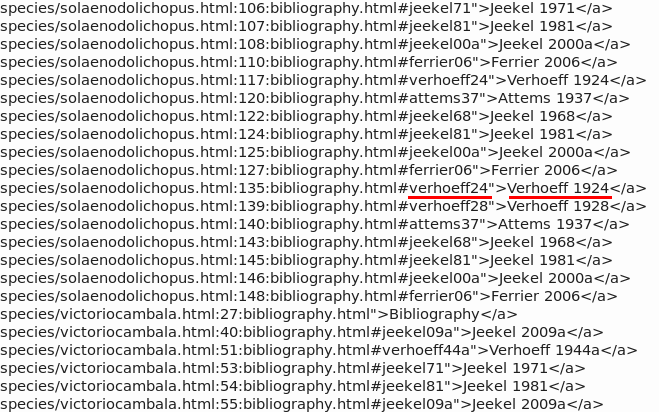
grep -r -o -n 'bibliography.*a>' species > ~/Desktop/refs1.txt
The grep command searched for any text string beginning with 'bibliography' and ending with 'a>'. The -r option told grep to look through all the webpage files (currently 105 of them) in the 'species' folder. The -o option meant 'report back with just the looked-for string, not the whole line containing that string'. The -n option told grep to also report the line number in which the string appears on its webpage. Finally, the results were sent as a text file, refs1.txt, to my desktop.
Part of refs1.txt is shown in the first screenshot. The line with the red underlining says that on line 135 of the webpage 'solaenodolichopus.html' in the 'species' folder there's a link which sends the user to the 'verhoeff24' target on the bibliography page when the user clicks the text 'Verhoeff 1924'. So far so good...
[Why didn't I start the search string with '#'? Because many of my webpages have inline span elements containing style items with '#', like "color:#006633".]
#Cleaning the harvest
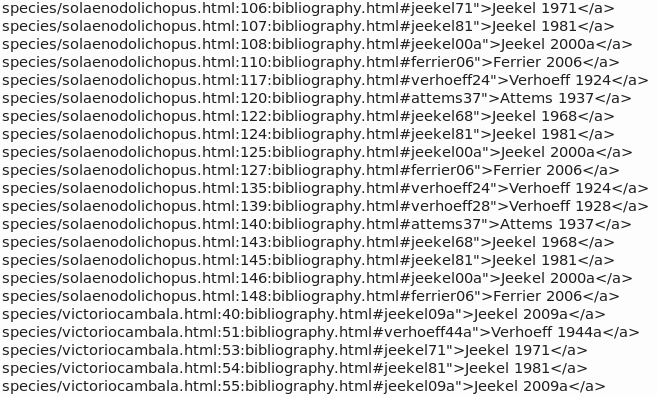
Notice in the first screenshot that grep also picked up the link (there's one on every page on the website) which takes the user to the top of the bibliography page, e.g. Bibliography. The easiest way to remove those uninteresting links was with grep, this time searching for part of that link string and 'inverting' the search with the -v option:
grep -v 'bibliography.html">Bibliography' ~/Desktop/refs1.txt > ~/Desktop/refs2.txt
That neatly trimmed away the uninteresting link from each page to create refs2.txt (second screenshot).
The next step was to open refs2.txt in a text editor (I use gedit), then (1) change all text to lower case, (2) remove the '' at the ends of lines and (3) replace the string ">" with #. The result was saved as refs3.txt and part of it is shown in the third screenshot.
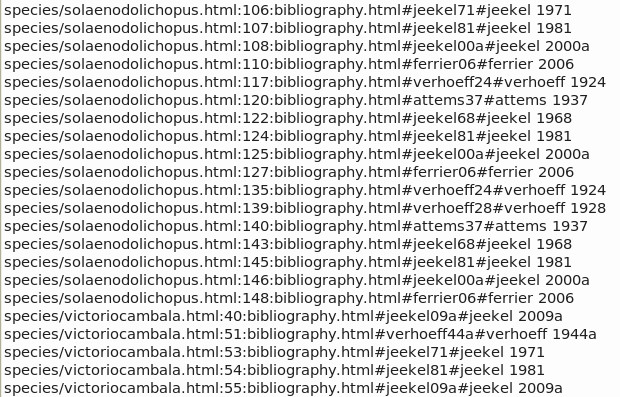
#On to a spreadsheet
Why all the text tweaking? Because refs3.txt, as shown in that third screenshot, could now be quickly copied and pasted into a spreadsheet and split up using the # character as a field delimiter. The fourth screenshot shows the result in the Gnumeric spreadsheet program.
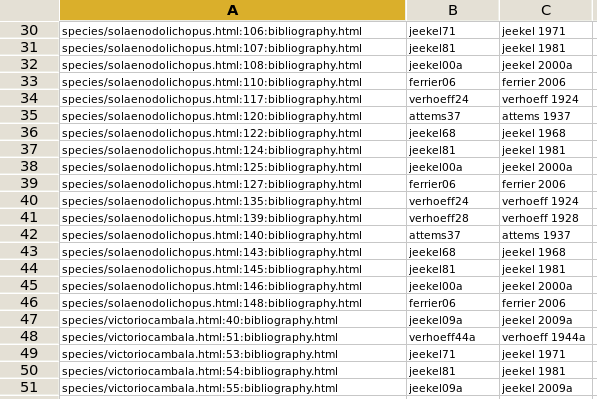
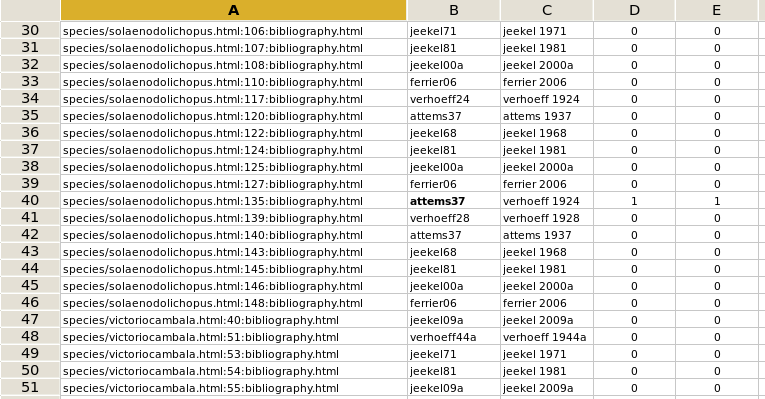
Column B in the spreadsheet contained the anchor text on the bibliography page, which the browser will look for, and column C contained the link text, with decapitalised names. These two entries were then compared with two simple functions in the next columns, as listed here for line 30:
column D: if(left(B30,4)=left(C30,4),0,1)
column E: if(right(B30,2)=right(C30,2),0,1)
The function in column D checked to see if the first four characters on the left (the first four characters of the author's name) are the same. The column E function checked the last two characters (from the year text). In the fifth screenshot I've deliberately messed up row 40 to show how the test works: the two mismatches are flagged with '1'.
#Not perfect, but...
I sorted the spreadsheet to locate any '1's and see what the problems were. In some cases the link text was just the year (e.g., '2010' instead of 'Bloggs 2010'), and I got a mismatch in the first column. In a few other cases the webpage text had more than one link per line, so grep harvested the string from the 'bibliography' in the first link to the end of the last link. These apparent mismatches might be called false positives. There weren't so many that checking them was tedious, and most of the thousands of links passed the test with two '0's.
The test might also have had false negatives. For example, the following misdirection would have passed: Johnson 2011. The bibliography – luckily – didn't contain potential confusers.
To sum up, the procedure I used to spot misdirections was to first harvest all URLs and their associated link texts, then split those two text strings between two fields in a spreadsheet and test for 'sameness'. It's an imperfect but fast procedure that would suit big websites with lots of links, where checking each link would be mind-numbingly slow.
Alas, the procedure won't work at all with software-generated URLs like the ones below. Which is another reason I like to build my own sites!