Recently, I collected some data from Sourceforge, hoping to find evidence for the importance of copyleft. But I found something surprising: although there's plenty of evidence that many developers believe in the power of copyleft, the one measure I could derive of how much copyleft actually works showed that copyleft made no difference whatsoever! If true, this means a lot of free software's social theory is wrong and many things will have to be re-thought.
One of the fundamental ideas in free software circles is that copyleft—the requirement that improvements to free software remain free to the community—is essential (or at least very important) for ensuring that the public good of free software production isn't co-opted and privatized ("hijacking" I like to call it, in response to those who dub copyright infringement "piracy").
However, while this sounds good in theory, it's a challenge to prove it quantitatively.
One of the fundamental ideas in free software circles is that copyleft is essential
Fortunately, there is Sourceforge. All Sourceforge projects are tagged with metadata for things like licensing, maturity level, category of application, category of target users, and so on. Sourceforge also collects some objective statistics, via traffic analysis of the projects' web services. By doing careful searches using the Trove Software Map and filters, it's possible to tease out some useful statistics.
Since this is a magazine column and not a scientific paper, I'll start with a results summary and conclusions first. At the end, I'll summarize my methods for those who are interested.
Copyleft is certainly popular
The easiest thing to test is "How popular are copyleft licenses?" After all, if many developers use them, that is some suggestion that they are a good thing. It means, basically, that many developers (or at least the people who start free software projects) like copyleft licenses.
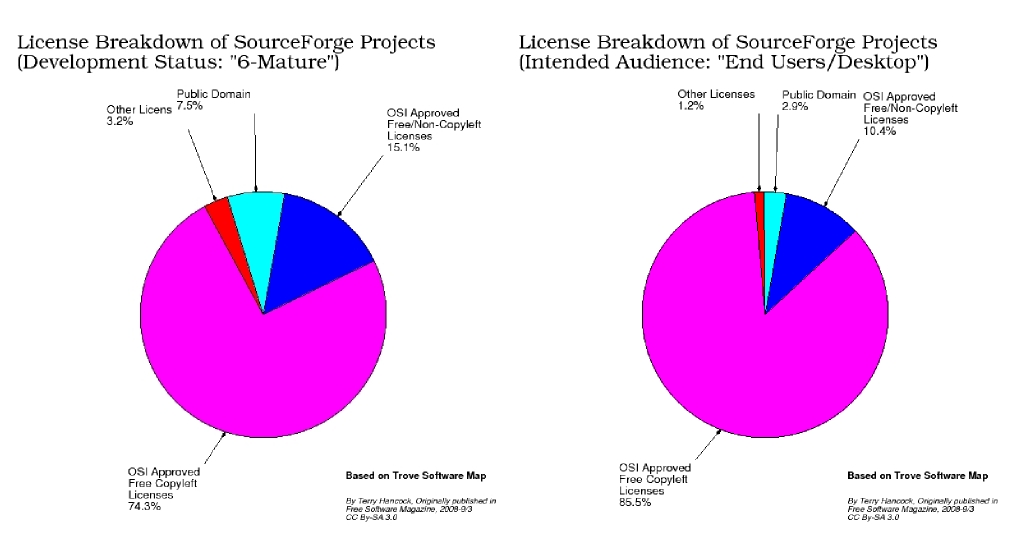
Approximately 80% of all the projects on Sourceforge are under "Free/Copyleft" licenses. You can cut this down in many different ways according to maturity and expected audience. Perhaps surprisingly, there isn't a lot of variation: the lowest copyleft-rates were for "projects aimed at developers" (about 75.9% are copylefted) and "mature projects" (74.3%) while the highest were "projects aimed at desktop end-users" (85.5%) and "maturity level '4-Beta'" (81.1%). "Projects with downloadable files" were about 81.0% copylefted. So "about 80%" is a very good description of the whole picture.
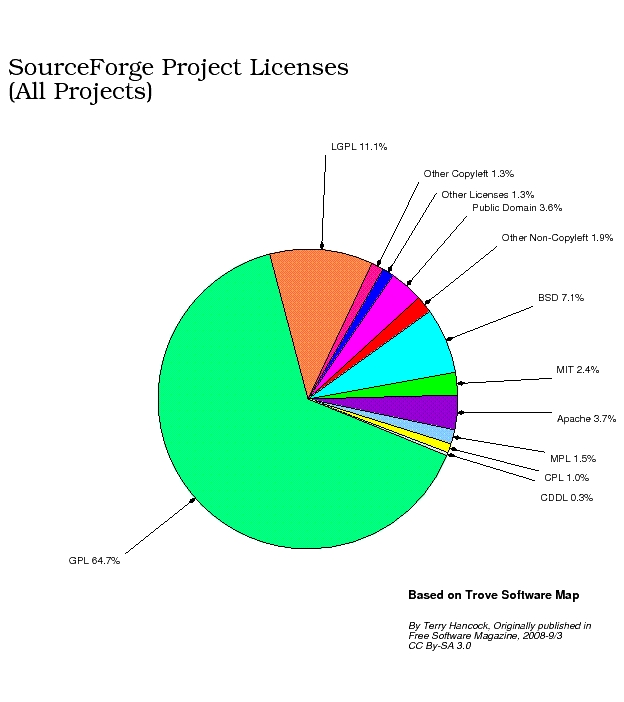
Of the total, almost two-thirds (64.7%) were licensed under the one most popular copyleft license, the GNU General Public License, and another 11.1% were under its companion the GNU Lesser General Public License (often used for libraries, because it allows for linking with proprietary programs). All told, about 92% of the licenses were "GPL Compatible", which means that, while they weren't necessarily GPL themselves, it would be legal to include them into a GPL project. That number includes quite a few non-copyleft licenses (such as the most popular non-copyleft licenses: BSD (7.1%), Apache (3.7%), and MIT/X11 (2.4%)).
So it's fair to say that many, many developers trust to copyleft when they start a project.
But what does it actually buy you?
If you ask most developers, they'll say they want a copyleft, because they want to avoid their work being co-opted or exploited (or even "hijacked"). That implies an assumption that a copyleft license will encourage more people to feel more comfortable about contributing their work to the project.
I started out with a basic hypothesis that: "Copyleft encourages contributions (because it eliminates fear of co-option of ones work)"
It has been suggested, for example, that the greater size and activity of the GNU/Linux community, versus the much smaller BSD Unix community, is explained by this.
I wanted a way to test this.
So, I started out with a basic hypothesis that: "Copyleft encourages contributions (because it eliminates fear of co-option of ones work)".
That led me to a working hypothesis that: "Copyleft projects will be more active than non-copyleft projects", and finally to the much more specific hypothesis "Copyleft projects on Sourceforge will have higher median activity scores than Non-Copyleft projects".
And that hypothesis is testable with the data I have available. Sourceforge tracks traffic data for projects, and assigns them an "activity" score based on it. This score is normalized to a "percentile", based on the average activity level of all Sourceforge projects. I haven't made an extensive study of the formula that goes into this activity level calculation, but I have included it in the references (the formula is published). It doesn't appear very surprising: things such as home page visits, CVS commits, and so on are collected.
Using the tools on the site, I was able to calculate the median and quartile "activity levels" for my four license categories: "Free/Non-Copyleft", "Free/Copyleft", "Public Domain", and "Other". The results took me a little by surprise:
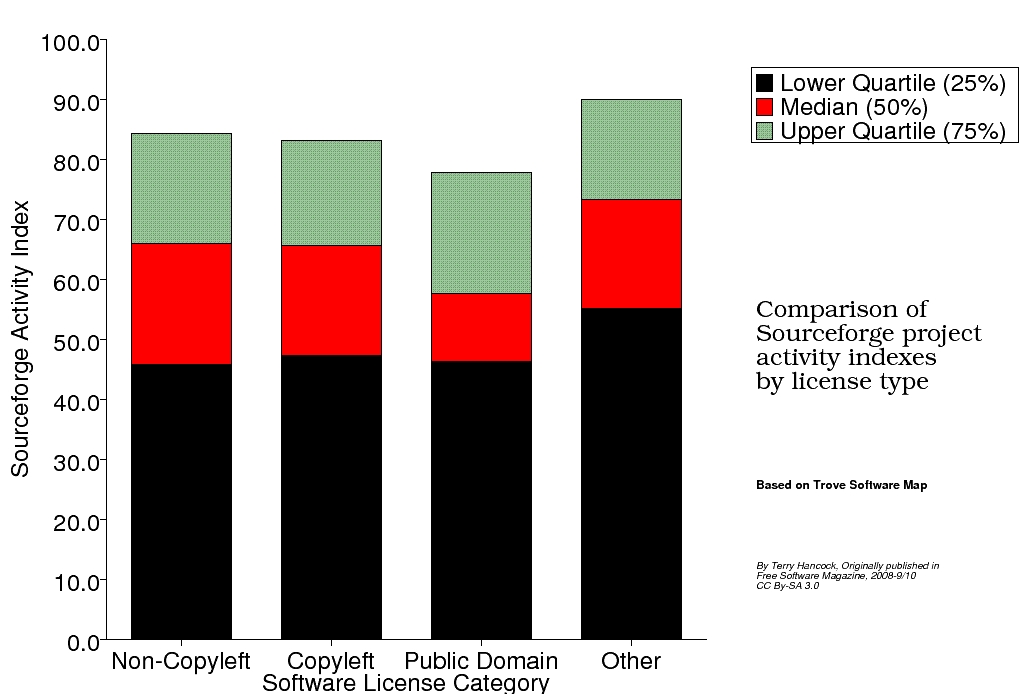
The same data is tabulated below:
| ACTIVITY PERCENTILES | Lower Quartile | Median | Upper Quartile |
|---|---|---|---|
| Copyleft | 47.2% | 65.6% | 83.1% |
| Non-Copyleft | 45.7% | 66.0% | 84.3% |
| Public Domain | 46.3% | 57.6% | 77.7% |
| Other | 55.1% | 73.3% | 90.0% |
For all intents and purposes, the "Copyleft" and "Non-Copyleft" projects are the same! Not only are the medians the same, but the quartiles (which measure the spread of the activity curve) are also the same.
For all intents and purposes, the "Copyleft" and "Non-Copyleft" projects are the same!
There's a greater difference between either and the "Public Domain" and "Other" categories. I'm not really able to account for that either. One possibility for the "Other" category is that many of the projects so labeled consist of projects with multiple licenses (some of these are games, with Creative Commons licenses applying to the "content" while another free license, often the GPL, applies to the "engine"). This might suggest that more thought went into their categorization, which would select for more "serious" projects. Or it might mean that multimedia projects are easier to contribute to.
So far, I haven't found anything wrong with my technique, so I am inclined to accept that these values are genuine. So what does that mean?
Copyleft has no practical advantage?
Well, there are basically three possibilities:
1. Copyleft doesn't work
If the data truly supports the idea that non-copyleft projects have just as much activity as copyleft projects do, then it suggests that copyleft isn't really giving us any material benefit. Despite the myth, people don't care about co-option or exploitation of their contributions, and will contribute anyway. That being the case, it suggests that we should re-think whether copyleft is a good idea (after all, it does carry some burdens).
It would also mean that we have to find an alternate explanation for the relative success of copylefted projects like GNU/Linux versus their non-copylefted counterparts, like BSD Unix.
Perhaps the Free Software Movement, with its insistence on copylefting software is basically just a cult religion, and people are drawn to it by charisma and faith, regardless of the actual evidence?
Maybe it's all just the effect of marketing? Maybe GNU/Linux is simply more popular because people talk about it more? Perhaps the Free Software Movement, with its insistence on copylefting software is basically just a cult religion, and people are drawn to it by charisma and faith, regardless of the actual evidence?
2. Copyleft does work, but somehow the effect doesn't show up in Sourceforge activity
The second possibility is that the activity figures are indeed correct, but (somehow) this doesn't reflect the actual impact of copyleft. Perhaps copyleft only kicks in for extremely popular products, with very high market value and lots of developers? Or perhaps copyleft affects contributory behaviors that Sourceforge's activity index doesn't measure? The question here is over the chain of hypotheses that I listed at the beginning of this article: does each really imply the next, or is there some disconnect along the way?
Perhaps copyleft only kicks in for extremely popular products, with very high market value and lots of developers?
Most projects hosted on Sourceforge are small with only one or two developers. Though this is certainly my impression from experience, it is much harder to prove, since Sourceforge's search engine doesn't let you filter based on number of developers.
However, they do include the data on the main project pages, and it's possible to do a Google search of the site. Google's index of the site is very incomplete, however, only showing about 200 projects out of over 120,000 (i.e. less than 0.2%). That might be enough data if the sample were random, though it's not clear that it is (if, for example, Google cataloged popular pages, then it would probably be skewed towards larger projects). However, it should give some rough idea of the distribution, as shown in the histogram below.
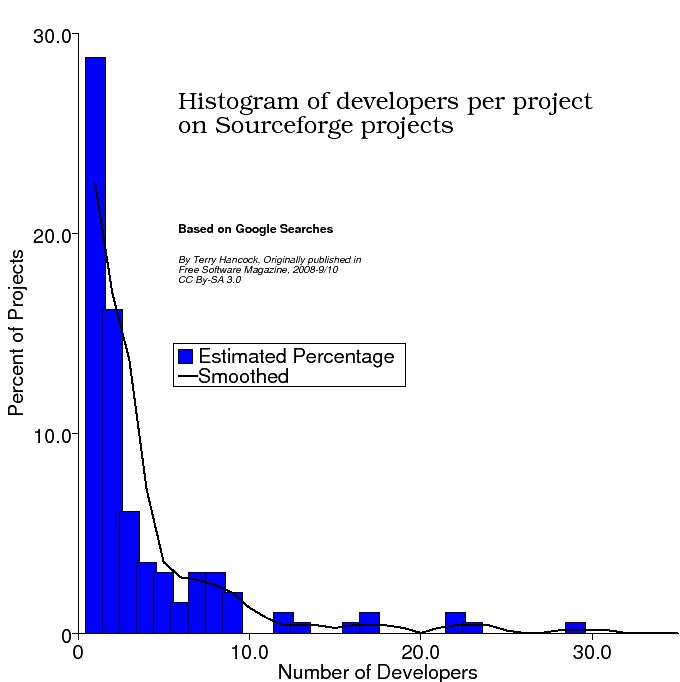
Now, this does show that small projects dominate, but not to the extreme that you'd expect everything else to be lost in the noise. Single developer projects make up only about 30% according to this chart. Still, it might be enough to muddy the impact of copyleft on participation, if only the largest projects were appreciably affected.
3. Something is wrong with the experimental technique
Lastly, of course, there is always the lurking gremlin of bad experimental design. I could've done something really dumb, so that the numbers I measured don't actually mean what I think they mean.
Lastly, of course, there is always the lurking gremlin of bad experimental design
I do believe that the formula for calculating the activity score is normalized against the entire body of Sourceforge projects, and is therefore effectively constant for the purposes of this study. It would be prohibitively computationally expensive for Sourceforge to do it any other way.
The activity scoring system is somewhat documented. See:
for more information on how the activity indexes are calculated. These articles lead me to believe that the numbers are absolute enough to be compared between different selection sets, as I have done here.
What do you think?
I'm putting this out here for you to think about: either it means something rather unexpected about copyleft (or should we have expected it?), or it means something weird and difficult to explain is going on. Please leave a comment if you want to suggest a new hypothesis, or offer an explanation for the results, or suggest some way in which my methods are flawed. I'm genuinely interested in refining the results. This was a quick ad hoc study, and I don't pretend that I've dotted every 'i' and crossed every 't', there's certainly a possibility of error on my part.
Observational Methods
As promised, here's how I did the research...
Sorting out the licenses
Sourceforge's Trove system breaks licenses down by type into "OSI Approved License", "Public Domain", and "Other/Proprietary". The OSI category, unfortunately, contains both copyleft and non-copyleft licenses. Therefore, the only way to make the distinction was to look up each of the listed licenses (all 72 of the OSI approved licenses!), and decide which category it belonged to. Then, each appropriate license can be "excluded" or "required", using the Trove system. I got these results by excluding all the licenses that didn't match my criteria (the numbers for "Copyleft", for example, are the results when all of the "Non-Copyleft" licenses, the "Public Domain", and the "Other/Proprietary" licenses have been excluded.
Technically, of course, there is not a one-to-one correspondence between projects and licenses. Sourceforge allows having multiple licenses on a single project. However, only a very small fraction of projects are affected. The biggest exception to this is the figures for "Other/Proprietary": many of those projects are actually dual-licensed projects, where one license (such as the GPL) applies to "code" while a different sort of license (such as Creative Commons By-SA) applies to the "content".
Activity Levels
The main result here is the difference (or lack of difference) in median activity levels between copyleft and non-copyleft licenses. The search engine doesn't directly deliver this information. However, using the advanced search, it is possible to restrict searches to ranges of activity levels, using a search term like this: percentile:[000.0 TO 050.0] to limit to activities between 0% and 50%. The resulting search will tell how many projects fall into this range.
If you record the number of projects returned without the activity range limitation, then divide by two, you will have the number of projects which will be returned by a search which limits the search to activities below the median. This is by definition true, because the median is the "50th percentile": the median activity level is defined to be higher than half the projects and lower than the other half. The quartiles are defined similarly, except for the 25th and 75th percentiles.
So, all that's necessary is to do a binary search: split the range, see if you're low or high, then split the appropriate remaining range, and keep going until you reach the level of precision you want. I determined my figures to 0.1% in this way—more than enough precision for this kind of study.
Remaining Questions
One thing I would've liked to have done, would be to compare projects with large numbers of developers, excluding the smaller projects. There's no filter or search method provided for that, and the free text search fields that Sourceforge provides only compare against the project name and description fields.
Certainly Sourceforge does have this information in their database and it's not a secret: every project has the number of developers as public metadata for the project. But there's no easy way to search for it without crawling the site (which is considered very bad form, because it would tax the servers, which are already pretty busy). I may be able to get access to bulk information from which this kind of result can be derived (I've already asked, but it's too soon to expect a response).
Giving up on copyleft?
So, is copyleft a bad idea? Well, once the cat's out of the bag, you can't put it back in: if you release without a copyleft, you can't easily put it back on your work. Also, copyleft can be viewed as a kind of insurance against a possibly unlikely, but unpleasant occurrence. Maybe that's all it is. Then again, maybe that's enough.
Also, one line of evidence does not tear down an entire theory. There are a number of indirect evidences that copyleft is useful, and the FSF does handle a few cases of GPL infringement (mostly settled out of court). So copyleft is definitely being used. The question here is whether it has a practical benefit of encouraging people to contribute to development projects.
For my own projects, I'm still favoring copyleft. But copyleft does have a cost: conflicts between different copyleft licenses, certain kinds of activities you can't (or can't easily) do with it (sometimes being incorporated into a proprietary project is good for your project). So, this information is certainly forcing me to re-think some of my assumptions.