In the previous posts, I have written about personal use of static code reviews via a GUI, in this case Eclipse. However, for large projects with hundreds of thousands of lines of code or more, with the code base being scattered amongst project teams, we have a problem. The economics of Quality Assurance demand a more mass analyzed and factory-efficient approach. Do things quick, hit the code, find the worst bugs and repair. The white box looking out, in combination with the functional or load testing black box methodologies looking in.
Note: this is Part 3. Feel free to read Part 2!
In this post I will tell you how to take your first steps using FindBugs. I also had the distinct pleasure of interviewing Bill Pugh, whose comments I find helpful and realistic.
FindBugs from the trenches
Findbugs can be run from the command line in such a simple and straightforward manner that you really wonder what all the fuss is about. Assuming you have Java 1.5 or above, simply download the .tgz package from http://findbugs.sourceforge.net/downloads.html and unpack under your home directory, for example:
cd ~
gunzip findbugs-1.3.2.tar.gz
tar xvf findbugs-1.3.2.tar
Do the same for your target application's Java binary version. For practice please try downloading the binary version of tomcat 5.5, uPortal, Sakai or whichever Java application you plan to deploy or test.
Once you have unpacked the binary, enter the application's top level directory and then unpack all the classes from all the jar files (java libraries).
From Bash/Ubuntu 7.10 the following command works:
cd location_of_binary
for i in `find . -name "*.jar"`; do unzip -n -d `dirname $i` $i;done;
Listing 3 is a helper script; please change the FINDBUG_HOME variable to suite.
#!/bin/bash
export FINDBUGS_HOME=~/apps/findbugs-1.3.2
$FINDBUGS_HOME/bin/findbugs -textui -maxHeap 700 -html -outputFile $1 $2
Listing 3: An example bash script
Now that all the classes are exposed, you can run FindBugs, mentioning the top level directory for the binary and the location of the final report.
-
-textuitells FindBugs to use the command line rather than to try and generate a GUI interface for use. -
-maxheapis the maximum amount of memory allocated. If you have a large project and a strong machine to run the review from then changing upward to say 2GB. 2048 is a solid idea. -
-htmlgenerates an HTML report; you can also generate in XML format which is easier for automatically processing for conversion for input, for example, into a database.
When the tool has finished with its comprehensive processing, it generates an HTML report mentioning every issue found and the location and a number of baseline statistics. Please review figure 3. with the current uPortal binary as an example.
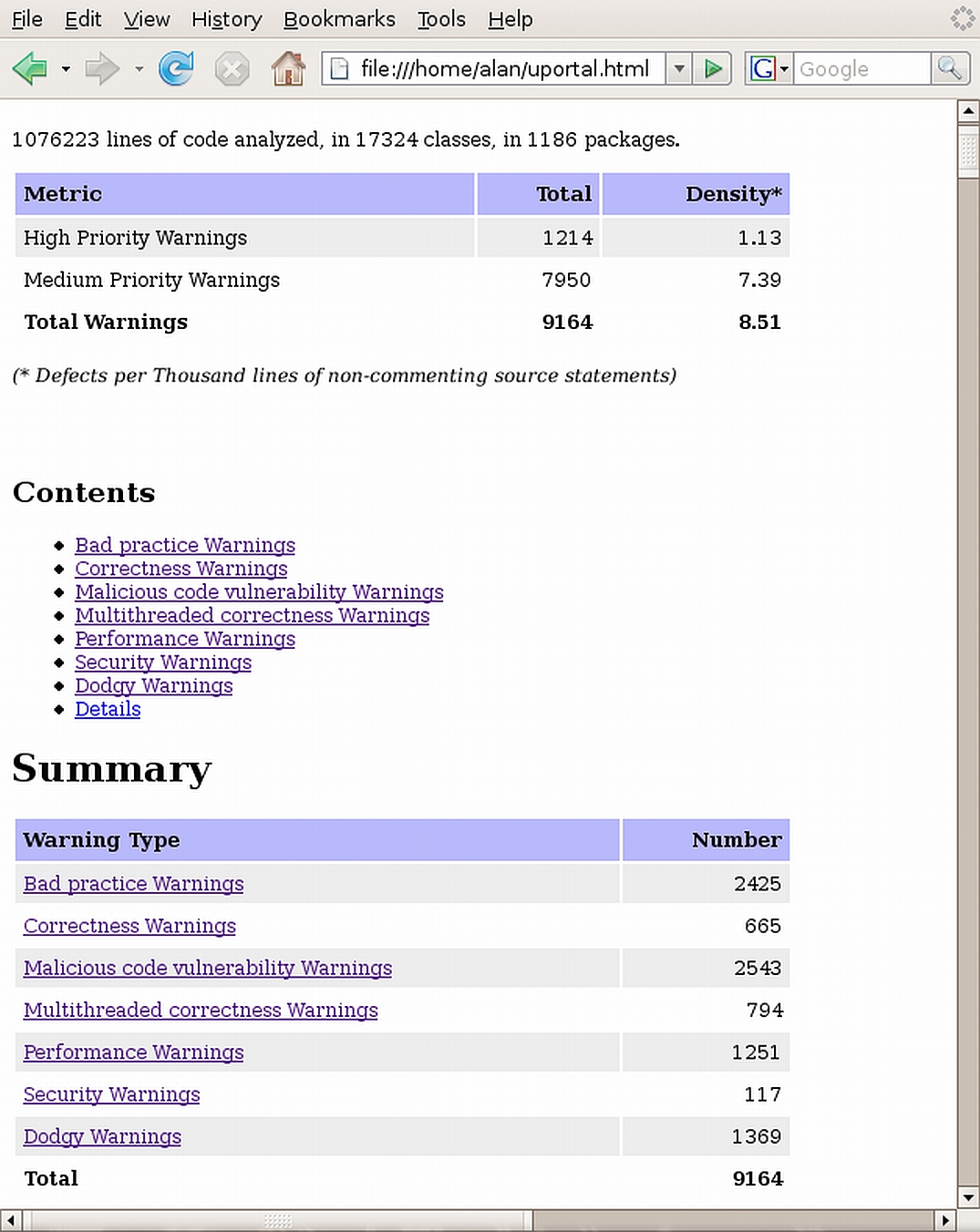
To start bug splattering, unpack a binary version of your Java application and the included Jar files. Let Findbugs rip and then read the generated report and finally choose which issues to solve. Of course later on, you will probably wish to effect a more complex workflow such as tracking bugs, placing reports into databases for easy querying, custom report generation, etc. When you have gained an appropriate level of experience I would advise you to look further at what Maven 2 site reports, Sonar, Xradar or QAlabs software can do on top of PMD and FindBugs. However, the simple approach mentioned here is quick and to the point, and better still cheap and easy to enact. It's a good approach that proves the validity of static code reviews before investing much more heavily in your own infrastructure.
Do not underestimate what has just been achieved. With a few commands you can analyse most modern binary versions of Java applications. Proprietary software will also find it hard to hide from the laser-guided searchlights.
Proprietary software will also find it hard to hide from the laser-guided searchlights.
At this point it is worth injecting some real-life experience into this article via an interview with the rather well educated Bill Pugh.
An Interview with Bill Pugh
[AMB] Can you tell the reader a little bit about yourself?
[BP] I got my PhD in Computer Science, with a minor in Theatre, from Cornell University in 1988 and have been a professor at the University of Maryland since then. I've enjoyed the freedom to work on lots of different topics as a faculty member. One of the results I'm still most pleased by was the invention of Skip Lists, a probabilistic data structure that provides functionality similar to balanced trees (and Concurrent Skip Lists were added to Java in Java 6).
[AMB] Do renown companies use--or have used--Findbugs?
[BP] The two biggest companies that make extensive use of it are Google and EBay. Both have published research papers about their use of it, and Google in particular has worked to develop a standard procedure and process for applying it to their entire Java code base (a very significant fraction of their code base). Sun and Oracle use it, although that use is project by project rather than any company wide policy. Lots of other companies all over the world use FindBugs. We have more than half a million downloads. Many of the financial services and other non-technology companies that use it won't let me disclose that they use it (I guess they worry that it would be admitting they have bugs in their code, which would be bad PR for them).
[AMB] For a newbie static code review reviewer, which two or three books or links would be the most helpful?
[BP] If you really want a book or source for users of static analysis tools, Secure Programming with Static Analysis, by Chess and West, is really the only thing out there. After that, it depends a lot on what your interests are. Java Programming Puzzlers and Effective Java are very good books about what mistakes to look for and how to write good code. PMD Applied is a good book about the PMD tool. Software Security: Building Security In is a good source for information about writing secure code.
[AMB] If a free software project quickly scanned their Java code base with Findbugs, in your opinion which couple of rules should they deal with first?
[BP] We have put a lot of work into making the high and medium priority correctness warnings for the issues that are most significant. There are many different kinds of bug patterns in those categories, none of which is particularly more important than the others.
We have recently added detectors for cross-site scripting and HTTP response-splitting vulnerabilities. If you write web applications and are concerned about those (or don't know what they are), then you should definitely look at those issues. We only look at obvious and blatant vulnerabilities, and the instances we find are generally exploitable.
[AMB] Findbugs reports defect densities of the scanned project. If I were a decision maker, should I use this metric to help inform my buying decision, for example 0.3 == Good 15 == Look elsewhere?
[BP] As far as defect density is concerned, we've only looked at the density of high/medium correctness issues. And you need to be really careful about just looking at simple metrics. In some particular project, something might have confused the analysis, or perhaps a project contains a huge number of instances of some particular issue that turn out not to be important or significant for that project.
That said, we generally find mature code has about 0.3-0.5 high/medium priority correctness issues per 1000 lines of non-commenting source statements (something FindBugs calculates, and is typically much lower than the number of lines of text in the source files). Generally, we find that about half the high/medium priority correctness is must/should fix issues. So if the density is much higher than what we typically see, and after looking at them you see that many of them are real issues, then yes, be worried. Looking over dozens of free software/open source projects, we didn't see any densities higher than 1.0 correctness issues per 100 lines NCSS.
[AMB] Have you any hints or tips on how, for QA'er having trouble motivating developers, to clean up their audited code?
[BP] We generally don't have a problem with that. The first thing I do is tell people that we routinely find mistakes in the code written by the very best programmers I know, as well as mistakes in my own code. And once people look at a couple of the high priority correctness issues we find, they generally motivate themselves.
The most important thing for successful use of FindBugs, or similar tools, is to: get them tuned so they report the issues you care about, and don't bother you with the other issues.
If looking at the full set of audit results is too much or too intimidating, do differential auditing: assume that the issues that made it through your last release to customers and made it through the entire Q&A process are unlikely to be significant, and audit just the issues that have been introduced since then (FindBugs has a number of features to allow computation of differential issue sets). Once you've done then, set up a continuous build system like Hudson that will flag, for each build, the FindBugs issues new to that build.
Once you've done then, set up a continuous build system like Hudson that will flag, for each build, the FindBugs issues new to that build
Finally
In the next exciting episode you will get to meet Tom Copeland one of the driving forces behind PMD and look at how to design a rule to enforce your perfection on the coding Universe.
Acknowledgments
I would like to thank my wife Hester vander Heijden for the brute force debug print statements on my forehead every time I forget to close the fridge and the Eclipse, FindBugs and PMD teams for building such excellent and easy to use products.