Ever need to code quickly? You can code Rexx like water—yet it’s powerful. Here’s everything you need to start, by studying real-world programming examples.
Script for success
One magical aspect of the free software movement is the many programming languages available. Among them are the scripting languages, languages designed for highly productive programming or “scripting”.
Popular free scripting languages include Perl, Python, Tcl/Tk, Ruby, Bash, Korn, and others. There is quite a variety because each offers its own unique combination of strengths, its own characteristics. Different languages meet different needs.
This article introduces one of the first scripting languages, one that continues to be popular world-wide. Rexx initially rose to prominence as the scripting language for IBM’s mainframe operating systems, the Amiga, OS/2, and other systems. Today nine free Rexx interpreters run on any platform, ranging from phones and handhelds, to laptops and PCs, all the way on up to servers and mainframes. Of course, this includes operating systems like GNU/Linux, Windows, and Unix.
Rexx’s big draw is that it is powerful yet easy to use. Many languages make this claim, but few achieve it. There exists a natural trade-off between power and ease-of-use—the more power designers cram into a language, the more complex that language becomes.
Rexx employs specific techniques to pack power while retaining ease of use:
- Minimal syntax
- Few rules restricting the code (aka free-formatting)
- Consistent, reliable behavior
- Common-sense defaults (for simplicity) that can easily be overridden (for power)
- A very small instruction set you can learn immediately, surrounded by larger, powerful function and object libraries you can learn over time
- Language extensibility through add-in function and class libraries. You use these external modules the same way you access built-in language features
- Modular and structured
- Standardized
I’m a big believer in “easy” languages—as long as they still meet my need for power. A language that is easy to code means higher productivity. You can script quickly. With modular design, I can write tons of small routines and evolve a large application in no time.
Easy languages lead to fewer errors. Fewer errors result in more reliable code.
Programs are quick to debug. And they are easier to maintain and upgrade as needs change. This is especially true with large programs.
Ever had to maintain someone else’s code written in a syntax-driven language? It can be tough, especially for large or undocumented programs. Many complex languages are very powerful, but programs written with them are hard to enhance and maintain. Scripts written in “easy languages” like Rexx can be modified much more easily. To the degree code grows and changes and needs to be updated, programs written in easier languages have longer lives than those encoded in powerful but complex languages.
Easy languages yield big benefits—even for experienced developers. While some consider it macho to work in powerful, complex languages, the best developers are wildly productive in easier languages. They script as fast as they think. Plus, the companies they work for prefer the maintainability of those languages. Organizations want living code—code that can adapt and be altered. Complex code doesn’t retain value once its originator “leaves the building”.
Varieties of Rexx
There are nine free Rexx interpreters. They fall into two broad categorizes:
- Procedural or “classic” Rexx
- Object-oriented
The tables below list the Rexx interpreters, the platforms on which they run, and a few of their major benefits.
| Regina | Nearly all platforms | Portable, standard, popular |
| Reginald | Windows | Excellent Windows integration |
| r4 | Windows | Includes many useful Windows tools |
| Rexx/imc | Linux, Unix, BSD | Industrial-strength, nice concise documentation plus tutorial |
| BRexx | Most platforms | Fastest Rexx, small footprint, lightweight |
| Rexx for Palm OS | Palm OS | Palm OS integration, text interface |
Free Rexx—classic interpreters
| Open Object Rexx | Linux, Unix, Windows | Fully OOP, highly popular download on SourceForge |
| roo! | Windows | Fully OOP, includes useful Windows tools |
| NetRexx | Any Java Virtual Machine | Non-standard. Integrates with Java, provides easy coding alternative |
Free Rexx—object-oriented interpreters
All the interpreters meet the Rexx standards (except for NetRexx, designed for Java integration). This means that your code is portable across platforms. Stick to the language standards (and limit the operating-system specific commands you issue from within the code), and your code runs anywhere. Your knowledge is transportable too, both across platforms and across the Rexx interpreters.
The first two object-oriented Rexx interpreters listed above are true supersets of the classic Rexx standards. They add complete object-orientation to standard Rexx. This includes objects, classes, messaging, single- and multiple- inheritance, data hiding, polymorphism, class libraries, and all the benefits of object-oriented programming. Since these interpreters meet the Rexx standards, classic Rexx programs run unchanged under object Rexx. This compatiblity both carries older procedural programs into the object-oriented world, and allows you to code whether or not you program using objects. You can mix procedural and object-oriented code however suits you.
NetRexx is unique. It is not standard Rexx but a “Rexx-like” language. Designed for Java integration, it runs on any Java Virtual Machine. It can use Java objects and be used to create objects used by Java programs. It offers an easy way to code for the Java environment.
You can download any of the Rexx interpreters from the Rexx site. The web site also offers hundreds of free add-in tools, and function and object libraries for Rexx, as well as sample code.
A sample program
Here’s a real-world example of how quick scripting can be useful. The other day I faced a dozen old Windows desktop computers running different versions of Compuserve software. (For those who remember the old dial-up days of a decade ago, Compuserve was a leading vendor for email and early internet access.)
My task was to somehow retrieve the contacts in the “address books” stored in the Compuserve software. I logged on to a few of the old machines and quickly determined that they ran ancient Compuserve software ranging from version 5 all the way back to version 2.
These versions of Compuserve all saved their address books in a single file named “addrbook.dat”. The difficulty is that the information in this file is encoded in a proprietary format. View it with Windows Notepad and you can see the contact information, but it is difficult to read because it’s interspersed with tons of unprintable and miscellaneous characters. Since I didn’t know the Compuserve address book format, I could only guess as to what the unprintable characters represent (length indicators?, flags?, field separators? I found a free program on the web called ForMorph Message Converter that exports old Compuserve information, but I never decoded the file format of addrbook.dat files. If anyone knows, please post it in the comments to this article.)
I decided to write a quick Rexx program to dump out the address book information in readable format. I have used classic (procedural) Rexx in the solution.
First, I wrote a quick script just to dump out the file to the screen as printable characters. This meant translating unprintable characters into their hexadecimal (base 16) equivalents. Then I could see what was actually in the address book files. I could, for example, match the printed hex characters to the character map available in Windows (view it by selecting Start→Programs→Accessories→Character Map). This quickly showed me what the unprintable characters in the file were.
The listing below shows what the program output looks like. Each line represents one character from the input file. Each line shows one character along with its hex equivalent to its immediate right. You can see that the letter “p” is “70” in hexadecimal, that the blank “ ” is “20” in hex, and that there are some mysterious characters with the hex value of “00” that do not show up on the screen at all. Only through this quick dump was I able to distinguish between hex blanks and the hex “00” characters in the file.
This particular file was corrupted but I was still able to view its contents. Now I’ve got a better idea of what’s in these address book files.
p 70
a 61
g 67
e 65
20
N 4E
® AE
A 41
. 2E
® AE
00
00
N 4E
...etc...
Let’s take a look at the code that produced this quick “hex dump”:
/***************************************************************/
/* Display file contents to the screen as hex characters */
/***************************************************************/
infile = 'addrbook.dat' /* The input file */
do while chars(infile) > 0 /* Read the input file, */
inbyte = charin(infile,,1) /* character by character */
say inbyte c2x(inbyte) /* Display each character */
end
In the code, the first line after the introductory comments sets a variable to the input file name.
The do while loop applies the built-in chars function to the input file. Its effect is to process the file while there are still characters to read.
Inside the do while loop, the charin built-in function reads one character from the input file into the variable named inbyte. The c2x function converts this single character into its hexadecimal equivalent, while the say function displays it on the screen. In this way, the program processes the input file, one character at a time, and displays each on the screen with its hexadecimal equivalent.
You can see why Rexx is quick to code in this sample code snippet:
- Minimal syntax
- Minimal coding rules and no required formatting
- No mandatory program sections
- Rexx automatically opens and closes files
- Variables do not have to be declared prior to use
An important principle is evident here. The behaviors of the last two points make good defaults but can easily be overridden—this is a technique Rexx employs to get simplicity to co-exist with power.
For example, need to override Rexx’s default file behaviors and manually open or close a file? No problem, Rexx provides the stream function for this purpose. Use it to specify any kind of file processing you like. Ditto for variables—you can declare them in advance of use and even issue a command requiring that all variables be initialized before use (useful in large programs where you don’t want to allow uninitialized variables and typos that accidentally become variables).
Rexx is ideal for quick scripting yet it allows you to write powerful programs. This is vital because there’s nothing more disappointing than using an easy programming language only to find yourself running out of power later.
An improved program
Now let’s expand the example program into something more useful. This version creates an easy-to-read version of the input file and displays it to the user through Windows Notepad.
This script is a generic “file viewer”. It converts any binary input file that contains some text into a more readable form, then displays the text to the user.
Figure 1 shows how the first part of the program output appears.
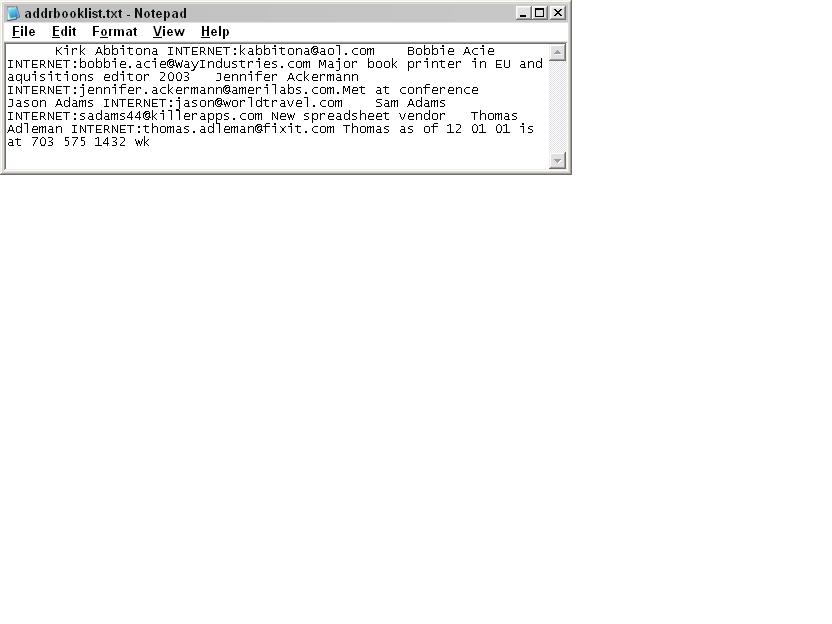
Names and email addresses have been altered for privacy reasons, but you can see that the program makes the meaningful information easily readable from the original hard-to-read input file.
In order to create a nice, viewable version of the input, the program masks out all the unprintable characters and miscellaneous punctuation. It converts them all to spaces. The script leaves unchanged only upper- and lower-case letters, the digits 0 through 9, and five meaningful punctuation characters: commas, underscores, colons, periods, and at signs (@). Here is the code:
/***************************************************************/
/* This displays the viewable information in an input file. */
/* */
/* Write printable characters to a file, changing unprintable */
/* characters and low-value punctuation into blanks (spaces). */
/* Let the user view the file via Windows Notepad editor. */
/* */
/***************************************************************/
infile = 'addrbook.dat' /* The input file */
outfile = 'addrbooklist.txt' /* The output file */
erase outfile /* Erase previous output */
do while chars(infile) > 0 /* Read the input file, */
inbyte = charin(infile,,1) /* character by character */
/* Convert input character-by-character to readable text */
if (inbyte >= '30'x & inbyte <= '5a'x) | ,
(inbyte >= '61'x & inbyte <= '7a'x) | ,
(inbyte = '2c'x) | (inbyte = '5f'x) | ,
(inbyte = '2e'x) then
rc = charout(outfile,inbyte) /* Write useful chars */
else /* to the output file, */
rc = charout(outfile,' ') /* convert others to blank*/
end
rc = charout(outfile) /* Close the output file */
notepad outfile /* Let user view output */
The heart of the program is the if statement in the middle of the script. This statement writes the printable characters to the output file while converting any non-printable or miscellaneous characters to blanks (spaces). The effect is a “cleaned up” file that is easily readable.
You can see that the if statement looks for certain ranges of hexadecimal characters that it leaves unchanged. The hex characters are denoted by the x that follows each, for example, '5f'x represents the underscore character in hexadecimal. Rexx handles all kinds of strings: character, alphanumeric, numeric, binary, hexadecimal, fixed-length, variable-length, whatever. Rexx facilitates problem-solving through string processing.
The Rexx line continuation character is the comma (,) so the commas tie together the if statement across the several lines on which it’s encoded. The logical and operation is denoted by the ampersand (&) while Rexx uses the vertical bar (|) to represent a logical or. In this program, I used a single, long if statement to determine which hex characters to keep because I thought it more clear to those who don’t know Rexx. But I could alternatively have used Rexx’s parsing, string translation, or regular expressions to perform the byte translations. (Regular expressions are not part of the base language but are routinely used as supplied through several free add-in packages.)
The script uses the charout function to write individual characters to the output file. I coded charout on the right-hand side of an equals sign, so that its return code will be assigned to the variable rc. In a more robust program you would always check return codes for events such as writing to files. You can always check whether or how any Rexx function worked through its return value.
The last line in the program invokes Windows Notepad to allow the user to easily view the output file. You can see how easy it is to issue operating system commands from within a Rexx script—simply encode them! Any statement Rexx does not understand it sends to the operating system for execution. So it’s very easy to integrate operating system commands into Rexx programs, or to use Rexx as a driver for system automation. As this example demonstrates, building upon existing OS commands and facilities is highly code-efficient.
Another example of an OS command occurs near the top of the program where the Windows erase command eliminates any output file from a previous run of the program. Rexx passes the erase command to Windows for execution after substituting in the proper value for the variable outfile. Rexx gives programmers full control over this substitution—given Rexx’s string manipulation capability, this gives you great power in issuing OS commands. You can programmatically create OS commands from within scripts and easily parse and analyze their outputs.
Finishing the job
Scripting lends itself to quickly solving parts of a problem with short scripts. Tie the small scripts together and you have a complete solution. The piping facility in operating systems like GNU/Linux or Windows can link your short scripts together into a complete solution. Why write one big complicated program? With an easy scripting language you don’t have to design all the logic for the complete solution before you start. Just start small and build from there.
That said, the final step in the solution is to take the output of the previous program as input to this new program, which then extracts and lists the names and email addresses. This was our initial goal. Here is sample output:
Abbitona, Kirk kabbitona@aol.com
Acie, Bobbie bobbie.acie@WayIndustries.com
Ackermann, Jennifer jennifer.ackermann@amerilabs.com
Adams, Jason jason@worldtravel.com
Adams, Sam sadams44@killerapps.com
Adleman, Thomas thomas.adleman@fixit.com
Here is the code that creates this list:
/****************************************************************/
/* Display the Names and Email Addresses from an old */
/* Compuserve address book. */
/* */
/****************************************************************/
string = linein('addrbooklist.txt') /* Read the input file */
do while pos('INTERNET:', string) > 0 /* Process each Entry */
/* Find start and end positions of the next email address */
pos_email_start = pos('INTERNET:', string)
pos_email_end = pos('.com', string) + 4
/* Calculate the length of the email address and extract it */
length_email = pos_email_end - pos_email_start
email = substr(string, pos_email_start, length_email)
email = delstr(email,1,9) /* Remove 'INTERNET' */
/* Extract the first and last names as: Last, First */
name_etc = substr(string, 1, pos_email_start-1)
name_etc = reverse(name_etc)
name = word(name_etc,2) || ' ,' || word(name_etc,1)
name = reverse(name)
name = left(name,20) /* Left-justify name */
say name email /* Display the Name and Email Address */
string = substr(string, pos_email_end) /* Adjust the string */
end
Here’s how this program works. The script reads the entire output file of the previous program in one statement by using the linein function. (Remember that there will be no end-of-line markers within the file because the previous program converted them all to spaces.) The program places this input into the variable named string.
Then the program processes each name and email address in the input string, one at a time, through its do while loop. Each time through that loop, the script breaks out one entry’s first and last names and email address. It does this by scanning for the phrase “INTERNET:” that occurs prior to each email address, and also by looking for the “.com” string at the end of the email address. The code excludes the optional “comments” associated with some entries. Then the script shortens the string to process by eliminating the entry it just printed, and it goes back to the top of the do while loop to process the next address book entry.
The program uses several Rexx string manipulation functions to identify and isolate information from the input string:
pos |
Returns the starting position of a search string within a string |
substr |
Returns a substring from within a string |
delstr |
Deletes part of a string |
reverse |
Reverses the characters in a string |
word |
Returns a blank-delimited word from within a string |
left |
Left-justifies a string |
String functions in the example program
I won’t walk you through the entire example, as its comments are probably sufficient to enable you to follow it. One trick I’d like to mention, though, is the use of the reverse function. The three parts of each address book entry are: name, email address, and optional comments. After each time through the do while loop, the program identifies and extracts the next name and email address from the input string. If the entry includes optional comments, these are left in the input string when the script processes the next address book entry. So, the script uses the reverse function to reverse-order the characters in the comments and name. Then with the names occuring first in the input string, the script can easily extract this information using the word function (once to retrieve the last name and the second time to retrieve the first name). After the script obtains the first and last names, it uses the reverse function one last time to properly order the characters in the names.
To learn more
You’ve seen how easy it is to write short scripts to solve small problems, and then to tie them together to solve a larger problem. It would be simple to enhance these scripts to handle special cases in the input data (for example, email addresses that do not start with the string “INTERNET:” or that do not end in the suffix “.com”). Rexx is ideal for this kind of iterative programming, as are other easy-to-code scripting languages.
But is Rexx powerful? If you still need to be convinced of this, read this article in Doctor Dobbs Journal showing how Rexx supports all kinds of data structures—based on simple dot notation. In Rexx, dot notation can represent arrays, trees, structures, records, lists, and other data structures. So you create all kinds of data structures in the same, simple manner—like this: data_structure.1 or data_structure.variable_A.variable_B.
Contrast this to syntax-driven languages, where each data structure adds its own unique syntax to the language. Power languages that add syntax for each different data structure typically end up with some pretty complex and unforgiving syntax.
Both approaches do the same job. Which is easier? This is the Rexx philosophy. Power through simplicity.
To learn more about Rexx, read this two-part language tutorial. Part I further describes Rexx and its features and varieties while Part II is an easy language tutorial. All the interpreter download web sites also offer nice language tutorials.
The simple examples in this article are hardly enough to get a feel for the language, much less showcase its features or its power. Download more sample code from the sources listed at this web site.
Scroll up on the same page and you’ll see where you can download all the Rexx interpreters discussed in this article. Hundreds of free tools are downloadable from there as well.
I recommend three key web sites. For Rexx information of all kinds (including downloads), visit RexxInfo.org. Other excellent web sites include the Rexx Language Association and the Open Object Rexx project web site for object-oriented programming.